ESP8266
信息安全
计算机组成原理
BitmapDrawable
文件批量重命名
单例模式
ssm
binder
自定义Toast
微控制器
Tableau
关键路径
jQuery
ThingsBoard
正射矫正
CMake include
日期类的实现
中断
proteus
汉诺塔
requests库
2024/4/11 17:52:58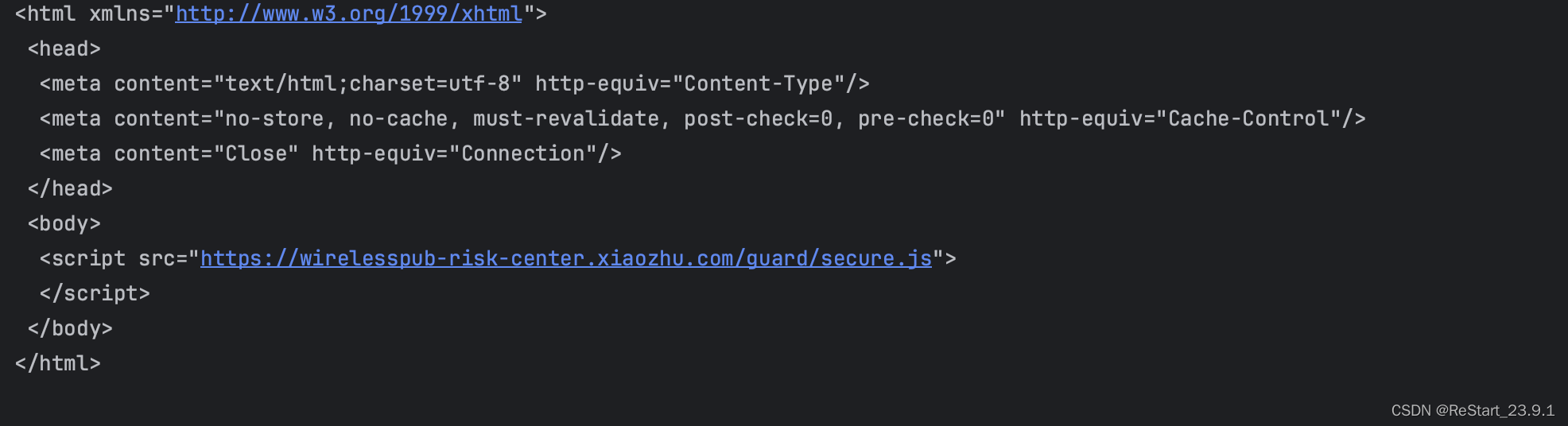
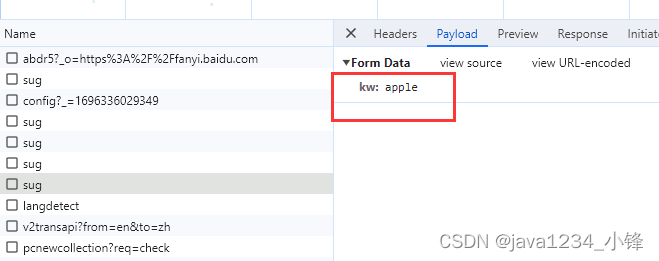
requests之post请求实例-百度翻译
视频版教程:一天掌握python爬虫【基础篇】 涵盖 requests、beautifulsoup、selenium
打开百度翻译网址,我们输入需要翻译的英文,谷歌 F12 打开开发者工具,network可以看到网络请求,我们需要找到请求的API,…

requests之get请求实例-百度搜索
视频版教程:一天掌握python爬虫【基础篇】 涵盖 requests、beautifulsoup、selenium
百度搜索请求地址:
https://www.baidu.com/s?wd宝马
如果我们直接用requests.get()进行访问,发现没有返回内容,因为百度服务器通过headers头…
【从零学习python 】92.使用Python的requests库发送HTTP请求和处理响应
文章目录 URL参数传递方式一:使用字典传递参数URL参数传递方式二:直接在URL中拼接参数获取响应头信息获取响应体数据a. 获取二进制数据b. 获取字符数据c. 获取JSON数据 进阶案例 URL参数传递方式一:使用字典传递参数
url https://www.apiop…
Python requests之代理
视频版教程:一天掌握python爬虫【基础篇】 涵盖 requests、beautifulsoup、selenium
很多网站和应用都有反爬虫策略,我们频繁的访问,一旦触发反爬虫策略,我们的IP就会被封掉。
我们为了应对反爬虫,可以使用代理。
代…
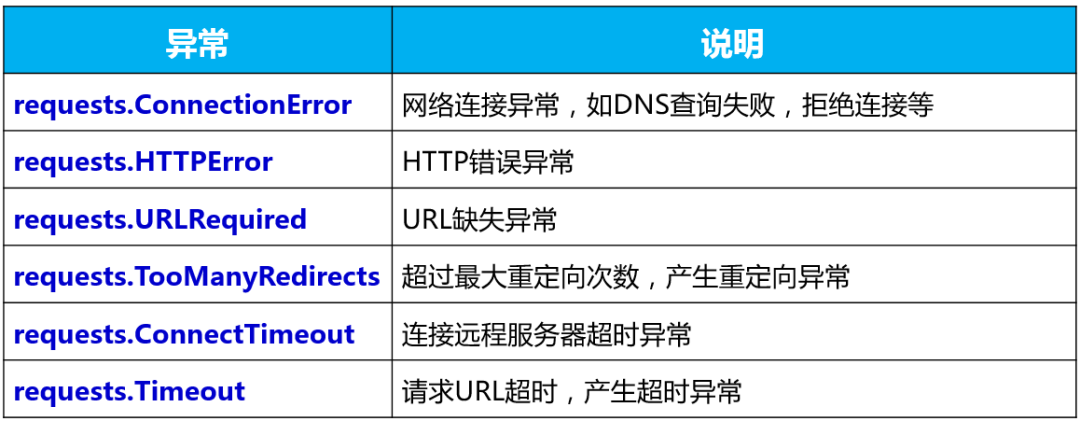
网络爬虫之Requests库详解(含多个案例)
网络爬虫是一种程序,它的主要目的是将互联网上的网页下载到本地并提取出相关数据。网络爬虫可以自动化的浏览网络中的信息,然后根据我们制定的规则下载和提取信息。
网络爬虫应用场景:搜索引擎、抓取商业数据、舆情分析、自动化任务。
HTTP…

【爬虫系列】Python 爬虫入门(1)
爬虫说明
我们知道,互联网时代,大量的数据信息会以网页作为载体而存在,有些公开而免费的数据比较适合采集,并经过有效处理之后,可用于数据分析、机器学习、科学决策等方面,而从网页中采集数据的利器&#…
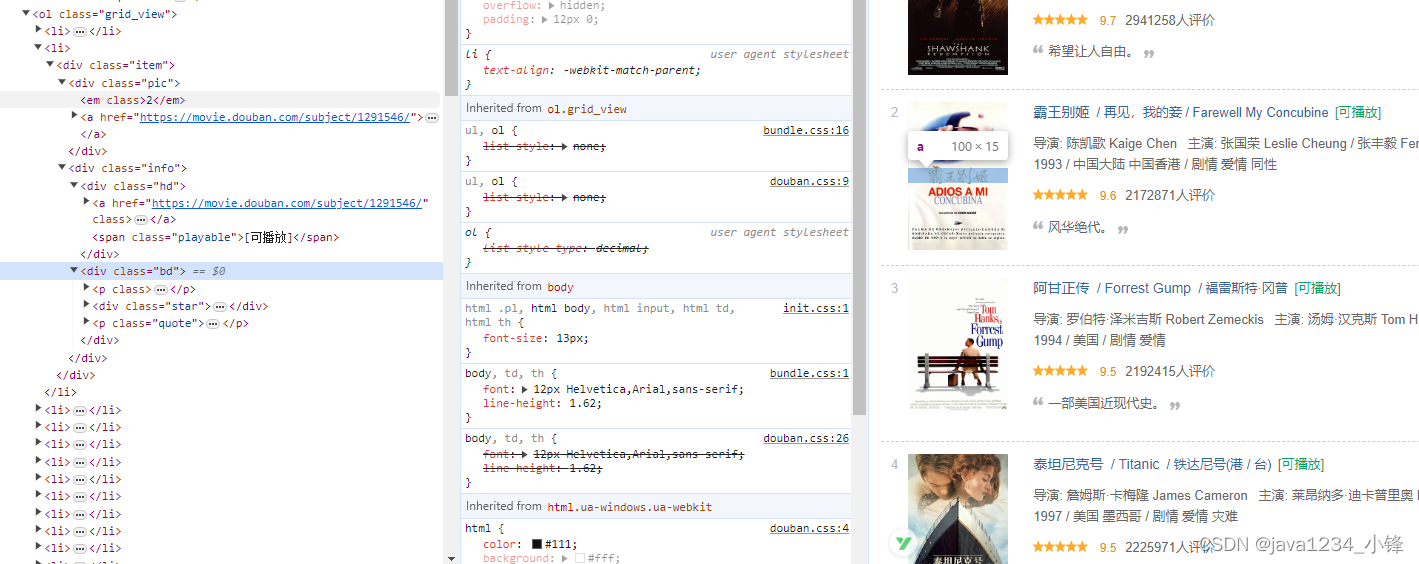
Python爬虫实战-批量爬取豆瓣电影排行信息
大家好,我是python222小锋老师。
近日锋哥又卷了一波Python实战课程-批量爬取豆瓣电影排行信息,主要是巩固下Python爬虫基础
视频版教程:
Python爬虫实战-批量爬取豆瓣电影排行信息 视频教程_哔哩哔哩_bilibiliPython爬虫实战-批量爬取豆瓣…
requests模块简介及安装
视频版教程:一天掌握python爬虫【基础篇】 涵盖 requests、beautifulsoup、selenium
Requests是一个优秀的Http开发库,支持HTTP连接保持和连接池,支持使用cookie保持会话,支持文件上传,支持自动确定响应内容的编码&am…
Python requests之Cookie
视频版教程:一天掌握python爬虫【基础篇】 涵盖 requests、beautifulsoup、selenium
在某些需要登录的网站或者或者应用,假如我们需要抓取登录后的内容,技术上本质通过session会话实现。服务器端存会话信息,浏览器通过Cookie携带…
Python requests之Session
视频版教程:一天掌握python爬虫【基础篇】 涵盖 requests、beautifulsoup、selenium
在 requests 里,session对象是一个非常常用的对象,这个对象代表一次用户会话:从客户端浏览器连接服务器开始,到客户端浏览器与服务…

3.简单的网页爬虫开发
目录
一、爬虫开发中的法律与道德问题
1.数据采集的法律问题
(1)妨害个人信息安全
(2)涉及国家安全信息
(3)妨害网站正常运行
(4)侵害他人利益
(5)内幕…